
All Posts
Dask Array: Scaling Up for Terabyte-Level Performance | Pangeo Showcase 2025-04-09
- 09 April 2025
Dask Array is the distributed array framework that has been the de-facto standard for running large-scale Xarray computations for many years. Nonetheless, the experience has been mixed. Over the last couple of months, Dask and Xarray maintainers have worked together to improve several shortcomings that have made workloads painful to run (or fail altogether) in the past. In this talk, we will look at some of the improvements that were made, and how they combine with other changes like P2P rechunking to make running array computations at the Terabyte scale effortless.
Dask ❤️ Xarray: Geoscience at Massive Scale | PyData Global 2024
- 05 December 2024
Doing geoscience is hard. It’s even harder if you have to figure out how to handle large amounts of data!
Xarray is an open-source Python library designed to simplify the handling of labeled multi-dimensional arrays, like raster geospatial data, making it a favorite among geoscientists. It allows these scientists to easily express their computations, and is backed by Dask, a Python library for parallel and distributed computing, to scale computations to entire clusters of machines.
Geoscience at Massive Scale | PyData Paris 2024
- 24 September 2024
When scaling geoscience workloads to large datasets, many scientists and developers reach for Dask, a library for distributed computing that plugs seamlessly into Xarray and offers an Array API that wraps NumPy. Featuring a distributed environment capable of running your workload on large clusters, Dask promises to make it easy to scale from prototyping on your laptop to analyzing petabyte-scale datasets.
Observability for Dask in Production | Pydata London 2024
- 15 June 2024
Debugging is hard. Distributed debugging is hell.
Dask is a popular library for parallel and distributed computing in Python. Dask is commonly used in data science, actual science, data engineering, and machine learning to distribute workloads onto clusters of many hundreds of workers with ease.
Dask performance benchmarking put to the test: Fixing a pandas bottleneck
- 23 June 2023
Getting notified of a significant performance regression the day before release sucks, but quickly identifying and resolving it feels great!
We were getting set up at our booth at JupyterCon 2023 when we received a notification: An engineer on our team had spotted a significant performance regression in Dask. With an impact of 40% increased runtime, it blocked the release planned for the next day!
Observability for Distributed Computing with Dask
- 16 May 2023
Debugging is hard. Distributed debugging is hell.
When dealing with unexpected issues in a distributed system, you need to understand what and why it happened, how interactions between individual pieces contributed to the problems, and how to avoid them in the future. In other words, you need observability. This article explains what observability is, how Dask implements it, what pain points remain, and how Coiled helps you overcome these.
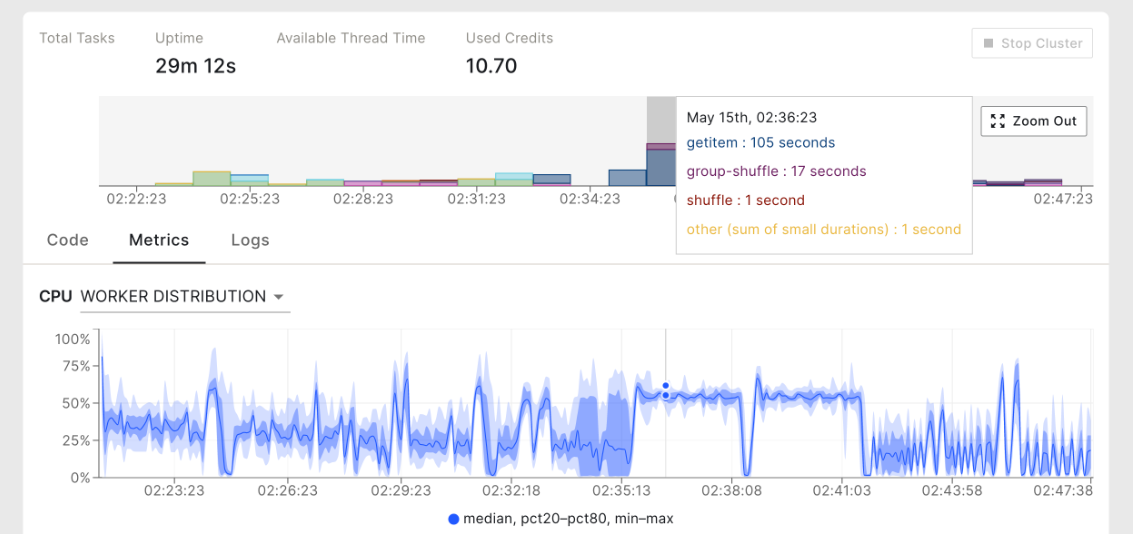
Observability for Distributed Computing with Dask | PyCon DE 2023
- 18 April 2023
Debugging is hard. Distributed debugging is hell.
Dask is a popular library for parallel and distributed computing in Python. Dask is commonly used in data science, actual science, data engineering, and machine learning to distribute workloads onto clusters of many hundreds of workers with ease.
Shuffling Large Data at Constant Memory in Dask | Dask Demo Day 2023-03
- 16 March 2023
Debugging is hard. Distributed debugging is hell.
Dask is a popular library for parallel and distributed computing in Python.
In this demo, we showcase the recent scalability and performance improvements in the dask.dataframe API that were enabled by my work on the new P2P shuffling system.
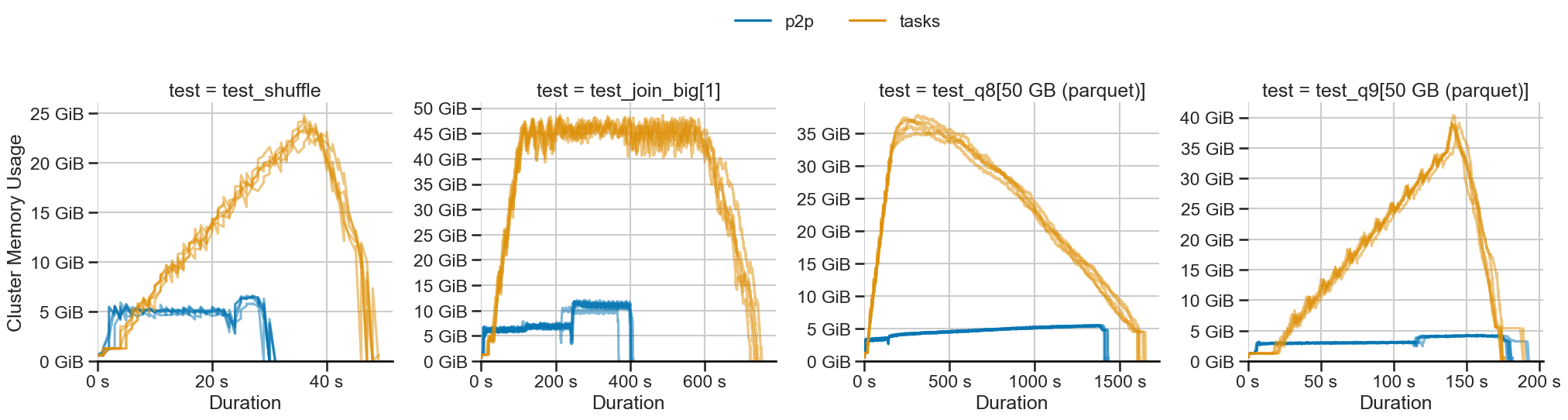
Shuffling large data at constant memory in Dask
- 15 March 2023
With release 2023.2.1, dask.dataframe introduces a new shuffling method called P2P, making sorts, merges, and joins faster and using constant memory.
Benchmarks show impressive improvements:
Rethinking Message Brokers on RDMA and NVM | ACM SIGMOD 2020 SRC
- 17 June 2020
Modern stream processing setups heavily rely on message brokers such as Apache Kafka or Apache Pulsar. These systems act as buffers and re-readable sources for downstream systems or applications. They are typically deployed on separate servers, requiring extra resources, and achieve persistence through disk-based storage, limiting achievable throughput. In our paper, we present Ghostwriter, a message broker that utilizes remote direct memory access (RDMA) and non-volatile memory (NVM) for highly efficient message transfer and storage. Utilizing the hardware characteristics of RDMA and NVM, we achieve data throughput that is only limited by the underlying hardware, while reducing computation and disaggregating storage and data transfer coordination. Ghostwriter achieves performance improvements of up to an order of magnitude in throughput and latency over state-of-the-art solutions.
Personalization versus ‘Filter Bubble’: The Influence of Personalization on the Quality of Search Queries
- 17 October 2018
With the accelerating speed of data generation, it becomes increasingly important to develop and improve techniques which help us find the most relevant information for any given question. Personalization as a solution is satisfactory for many use cases, such as on-site search in e-commerce or many queries on general purpose search engines. For certain queries, such as those on controversial political topics, however, result diversity is important to diminish the negative effects of personalization on civic discourse and democracy.